ModelSet - A dataset of software models for ML
An important shortcoming of current approaches for applying Machine Learning (ML) to address problems related to Model-Driven Engineering (MDE) is the lack of curated datasets of software models. We believe that there are several reasons for this, including the lack of large collections of good quality models, the difficulty to label models due to the required domain expertise, and the relative immaturity of the application of ML to MDE.
To address this problem (at least partially), we created ModelSet, which is a dataset of software models intented to help in the application of machine learning techniques to solve modelling tasks. Its main features are the following:
-
It contains more than 5,000 Ecore models (extracted from GitHub) and more than 5,000 UML models (extracted from GenMyModel).
-
The models have been labelled with its category, which represents a type of models sharing a similar application domain. The following charts contain a summary of the main categories (yes! people like building
state machinemeta-models and UML models describing theshoppingdomain!).

- In addition, ModelSet contains other labels which provides more semantic information. For instance, a model can be labelled with
category: statemachine, an additional label with valuetimedto indicate its variant, and another oneteachingto indicate that this particular model is being used for teaching purposes. In total, there are more than 28,000 labels.

We foresee some potential applications ModelSet, like the following:
- Classification approaches where labels are the target variables.
- Recommender systems (e.g., suggesting attribute names/types, etc.)
- Evaluation of clustering methods, in which the labels provide the ground truth about the clusters.
- Spurious model identification (i.e., using “dummy” labels)
- Evaluation of ML models via train-test-eval splitting in a stratified fashion using the labels.
- Train embeddings based on labels (i.e., for clone detection using the resulting vector).
- Empirical analysis of the modelling domain.
Anyway, we are sure that any researcher/modeller interested in ML will find other interesting areas of application.
If you need a larger collection of models for unsupervised approaches, you can also checkout the models available at MAR (click on the Status tab), where you will find more than 500,000 models of different types, including Ecore, UML, Archimate, BPMN, etc.
The details of ModelSet have been presented in this paper (which is freely available):
In this post we will explain some practical details about ModelSet: its structure, how to install it, how to load the dataset and an illustrative example to address classification task: inferring the category of a model.
Structure of the dataset
The dataset basically consists of: a) the raw models, b) the databases with the labels and information about the models and c) alternative serializations of the models (e.g., as text files). Here is the structure that you will find when you unzip the package.
[+] datasets
[+] dataset.ecore
[+] data
[+] ecore.db
- The database with the labels for the Ecore models
[+] analysis.db
- Statistics about the Ecore models
[+] dataset.genmymodel
[+] genmymodel.db
- The database with the labels for the UML models
[+] analysis.db
- Statistics about the UML models
[+] raw-data
[+] repo-ecore-all
- The .ecore models that has been labelled
[+] repo-genmymodel-uml
- The UML models that has been labelled, stored as .xmi files
[+] txt
- A mirror of raw-data but with 1-gram encoding of the models,
that is for each model a textual file with the strings of the model.
The databases are just SQLite databases that you can manipulate using any SQLite connector (e.g., in Java or Python).
The ecore.db and genmymodel.db files contain the databases with the labels associated to the models. You can open it with the sqlite command and the main part of the schema is simply:
sqlite> . schema
CREATE TABLE models (
id varchar(255) PRIMARY KEY,
repo varchar(255) NOT NULL,
filename text NOT NULL
);
CREATE TABLE metadata (
id varchar(255) PRIMARY KEY,
metadata text NOT NULL,
json text
);
The labels are stored in the metadata table, specifically the metadata column contains the labels as entered by the user who performed the labelling).
To facilitate its processing the json column contains a JSON representation of the labels. For instance, the following shows the labels in a model FaultTree.ecore serialized in JSON.
{
"category": ["fault-tree"],
"tags": ["safety", "hazard"],
"tool": ["osate2"]
}
It is possible to directly interact with the SQLite database to perform exploratory queries. For instance, the following query shows the number of models per category in the Ecore database. It uses the json_extract function to query the associated JSON that contains the metadata.
$ sqlite datasets/dataset.ecore/ecore.db
sqlite> select json_extract(md.json, '$.category[0]') as category, count(*) as total
from models m join metadata md on m.id = md.id
group by category
order by total desc;
category total
-------- -----
dummy 729
statemachine 392
petrinet 236
library 235
modelling 209
class-diagram 182
gpl 180
The analysis.db database has the same schema as the databases provided by MAR. It contains statistics about the model. In the case of the Ecore dataset, it also contains information about design smells found in each model.
$ sqlite3 repo-github-ecore/analysis.db
sqlite> . schema
CREATE TABLE models (
id varchar(255) PRIMARY KEY,
relative_file text NOT NULL,
hash text NOT NULL,
status varchar(255) NOT NULL,
metadata_document TEXT,
duplicate_of varchar(255)
);
CREATE TABLE stats (
id varchar(255) NOT NULL,
type varchar (255) NOT NULL,
count integer NOT NULL
);
The following query shows statistics about the models in the Ecore dataset. elements refers to the total number of elements, and the other types refers to meta-elements (e.g., EAttribute, EClass, etc.).
sqlite> select type, avg(count) from stats group by type;
type avg(count)
---------- ----------
attributes 16.31
classes 25.74
datatypes 1.23
elements 206.32
enum 1.24
packages 1.46
references 26.82
Example
In the rest of the post we will develop a concrete example, using ModelSet to build a classifier able to infer the category of a given Ecore model. We will use the ModelSet Python library to access the dataset and pandas and scikit-learn to manipulate the dataset and train the model.
The implementation of this example is available in our repository of ModelSet examples. You can download it here.
Installation
First of all, you need to download and install ModelSet.
- Download the package containing the raw models and the associated databases. Available at https://github.com/modelset/modelset-dataset/releases.
- Unzip the package in some local folder
- Install the Python library using pip. This will allow us to easily use ModelSet with standard ML libraries.
pip install modelset-py- If you have downloaded the source code of the library from GitHub repository ,
then use
sys.path.append("/path/to/modelset-py/src")as a shortcut to load it dynamically.
Loading the dataset
The ModelSet library offers a convenient interface to dump the contents of the underlying database into a dataframe. In particular, there are several features available in the output dataframe:
- The identifier of the model
- The category of the model (manually labelled). Reflects the domain of the model.
- Associated tags (zero or more manually labelled) which provide additional insights about the type of model.
- The language of the model (typically english)
- Basic stats. In the case of Ecore, number of elements, references, classes, attributes, packages, enumerations and datatypes
import sys
import pandas as pd
import os
import modelset.dataset as ds
dataset = ds.load(MODELSET_HOME, modeltype = 'ecore', selected_analysis = ['stats'])
# You can just use: ds.load(MODELSET_HOME, modeltype = 'ecore') to speedup the loading if you don't need the stats
Convert the dataset into a Pandas dataframe. There are two methods:
to_df()converts the complete dataset.to_normalized_df()only considers examples with a minimum number of examples (7 by default), written in english and removing special categories (dummy and unknown).
modelset_df = dataset.to_normalized_df()
# You can configure the elements of the dataframe:
# modelset_df = dataset.to_normalized_df(min_ocurrences_per_category = 7, languages = ['english'], remove_categories = ['dummy', 'unknown'])
modelset_df
| id | category | tags | language | references | elements | classes | attributes | packages | enum | datatypes | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | repo-ecore-all/data/AmerPecuj/MBSE/dk.dtu.comp... | petrinet | behaviour | english | 7 | 27 | 6 | 2 | 1 | 0 | 0 |
| 3 | repo-ecore-all/data/nlohmann/service-technolog... | petrinet | behaviour | english | 13 | 92 | 15 | 16 | 1 | 2 | 0 |
| 4 | repo-ecore-all/data/damenac/puzzle/examples/em... | education | domainmodel | english | 4 | 37 | 4 | 12 | 1 | 0 | 0 |
| 6 | repo-ecore-all/data/francoispfister/diagraph/o... | statemachine | behaviour | english | 7 | 87 | 9 | 13 | 1 | 0 | 0 |
| 8 | repo-ecore-all/data/gssi/metamodelsdataset-ECM... | petrinet | behaviour | english | 3 | 17 | 4 | 2 | 1 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 5468 | repo-ecore-all/data/Barros-Lucas/DSL_State_Int... | statemachine | behaviour | english | 3 | 22 | 5 | 4 | 1 | 0 | 0 |
| 5469 | repo-ecore-all/data/luciuscode/test/projectStr... | library | domainmodel | english | 4 | 34 | 6 | 3 | 1 | 1 | 0 |
| 5470 | repo-ecore-all/data/BlackBeltTechnology/emfbui... | company | NaN | english | 2 | 22 | 5 | 4 | 2 | 0 | 0 |
| 5473 | repo-ecore-all/data/mathiasnh/TDT4250-Assignme... | education | university|domainmodel | english | 24 | 101 | 11 | 12 | 1 | 2 | 0 |
| 5474 | repo-ecore-all/data/agacek/jkind-xtext/jkind.x... | simple-pl | expressions|types|lustre|programming | english | 55 | 214 | 44 | 14 | 1 | 0 | 0 |
4230 rows × 11 columns
Spliting the dataset
To train our model we are interested on the category attribute, which will be our target variable (the label that we want to predict) and we are going to use the model identifiers as input data because we will use them to lookup the corresponding textual representation (see below).
We need to split our dataset into training and test, so that we can evaluate later the accuracy of our model.
from sklearn.model_selection import train_test_split
# These dataframes are vectors
ids = modelset_df['id']
labels = modelset_df['category']
train_X, test_X, train_y, test_y = train_test_split(ids, labels, test_size=0.2, random_state=42)
Selecting features
A neural networks takes an input a numerical vector. So, we need a way to encode a model into a vector. A simple way is to use a TF-IDF encoding. Essentially, TF-IDF is a measure of the relevance of a word by comparing the number of times that a word appears in a document with respect to the number of documents in which the word appears.
To apply TF-IDF, the first thing that we need to do is to extract a textual representation of each model. We use the txt_file method to obtain the path to the text file associated with a given model. This is a feature provided by ModelSet: for each model there is already .txt which contains its 1-gram (i.e., the values of the string attributes).
Then, we can easily compute the TF-IDF using scikit-learn. The X and T matrices contain one row per model with a number of columns equals to the number of words in the models.
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.impute import SimpleImputer
train_filenames = [ dataset.txt_file(id) for id in train_X ]
test_filenames = [ dataset.txt_file(id) for id in test_X ]
vectorizer = TfidfVectorizer(input='filename', min_df = 2)
X = vectorizer.fit_transform(train_filenames)
T = vectorizer.transform(test_filenames)
# The output of the TF-IDF vectorization is a large matrix with len(train_X) rows and
# as many columns as words in the vocabulary
X.shape
(3384, 24810)
Training
We use a neural network with one hidden layer as our model. This is straightforward with scikit-learn.
from sklearn.neural_network import MLPClassifier
#input_layer = X.shape[1]
clf = MLPClassifier(solver='adam', learning_rate_init=0.01, hidden_layer_sizes=(64), random_state=1)
clf.fit(X, train_y)
Evaluation
from sklearn.metrics import classification_report,confusion_matrix
First, we evaluate the results obtained in the training set. In particular, we focus on the accuracy (the fraction of correctly classified examples).
predict_train = clf.predict(X)
# print(confusion_matrix(train_y, predict_train))
train_report = classification_report(train_y, predict_train, output_dict = True)
print("Training accuracy: ", train_report['accuracy'])
Training accuracy: 0.9994089834515366
Then, we evaluate the classifier over the test set. As can be seen the results are good, and in principle, we can assume that our model is ok and we can use it in practice.
predict_test = clf.predict(T)
test_report = classification_report(test_y, predict_test, output_dict = True)
print("Test accuracy: ", test_report['accuracy'])
Test accuracy: 0.9030732860520094
Practical usage
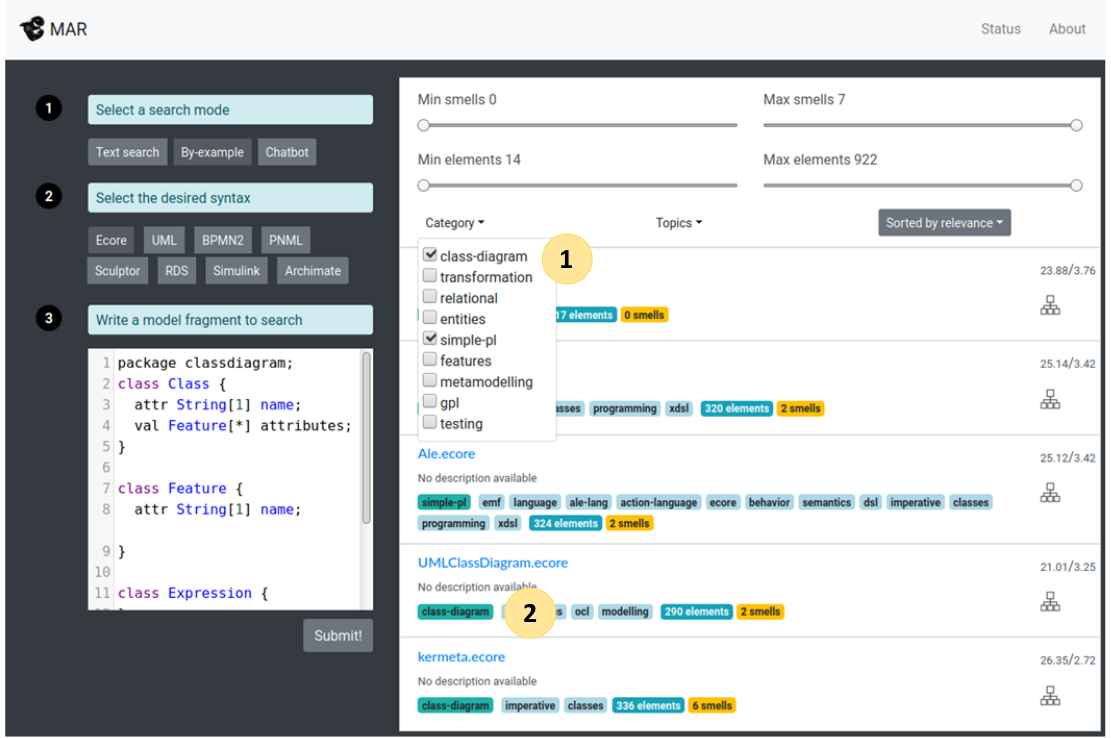
We have used ModelSet to enhance the MAR search engine. In particular, we use the model described above to infer the the category of the models shown as search results. In the image below the dropdown menu allows the user to filter the search results (label 1) and the little badges (label 2) are the categories and tags inferred per each model.
There are more than 17,000 Ecore models in MAR, so it is not feasiable to label all of them by hand. We have used the a ML model as the one trained in the example to infer the category of each model and so generate the associated badge.
Conclusion
This ends this introduction to ModelSet. The main goal has been to present it and to help potential users get started. There is still additional work to do, like labelling more models (see our Twitter bot if you want to help!) and building more examplary applications. Anyway, we hope that this is already a useful resource for the community.